集群模式(cluster)
Redis Cluster 的设计目标:
- 高性能:高性能是 Redis 赖以生存的看家本领,增加集群之后不能对性能产生太大影响,否则会得不尝失。
- 水平扩展:之前 Redis 集群不能水平扩展的缺点时常被人诟病,所以必须具备水平扩展。
- 高可用:在之前,高可用主要是通过 Redis Sentinel 来保障,Cluster 集群也应该具备 Sentinel 的监控、提醒、自动故障转移等功能。
有了 Cluster 的集群方案,使得 Redis 变成了真正的分布式 NoSql 数据库。
数据分区方案
为了使得集群能够水平扩展,首要解决的问题就是
如何将整个数据集按照一定的规则分配到多个节点上
,常用的数据分区的方法有:
普通哈希分区
普通的哈希分区比较简单,就是根据规定的哈希函数将数据哈希到指定的节点上,例如:现在有 3 个 Redis 结点 node1、node2、node3。我们的哈希函数采用取余法哈希
function hash(key) {
return key % 3
}
当写数据的时候,根据哈希函数写到对应的节点中,读数据的时候先计算出数据在哪个节点,然后再去对应的节点去取。我们发现当节点数固定的时候,该种数据分区的方案没有问题,当增加一个节点或删除一个节点的时候。
取余哈希函数的分母会改变,导致之前已分配的数据分区大量改变,并且造成大量的数据获取不到。所以该种方案很少使用。
一致性哈希分区
为了解决普通的哈希分区的缺点,提出了一致性哈希的概念。一致性哈希的核心原理是:将数据 key 和节点都通过哈希函数映射到 2^32 次方的环上
关于一致性哈希的原理,超出了本文探讨的范围,后续再写专门的文章来详解。
一致性哈希尽最大限度的解决了节点数改变带来的数据不一致的问题。
虚拟槽分区
Cluster 采用的正是这种分区的方式。虚拟槽分区巧妙的使用了哈希空间,使用分散度良好的哈希函数把
所有的数据映射到一个固定范围内的整数集合,整数定义为槽(slot),Redis Cluster 的槽范围是 0
~ 16383,槽是集群内的数据管理和迁移的基本单位。
每个节点负责一定数量的槽
。计算公式:
CRC16(key)&16383
每一个节点负责维护一部分槽及槽所映射的键值数据,如下图所示(图片来源于网络):
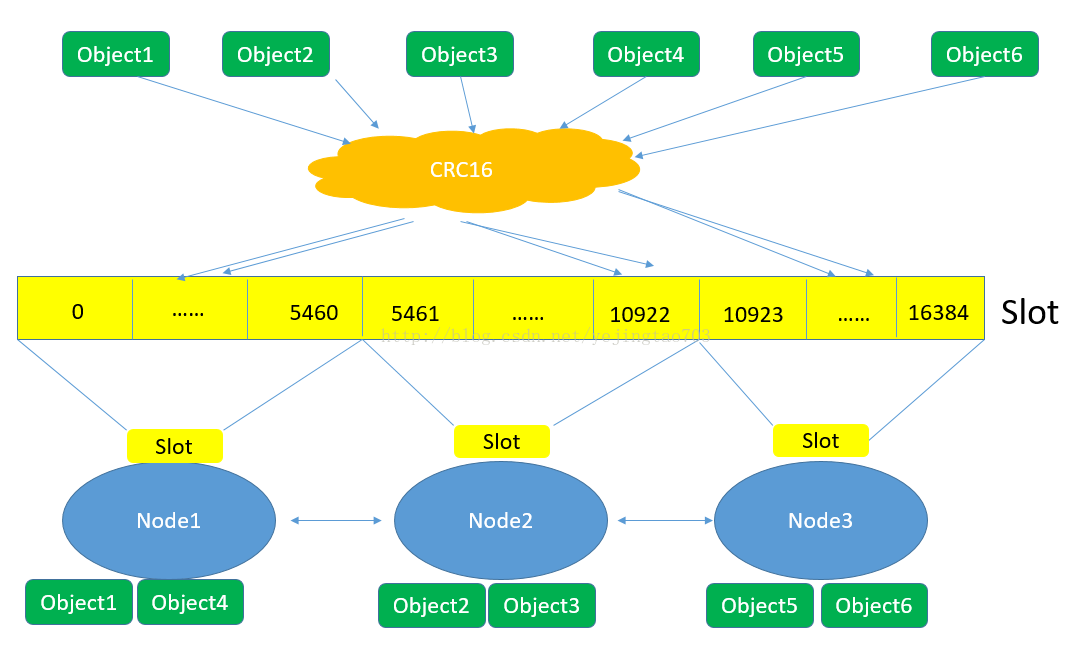
采用
哈希虚拟槽分区
的特性:
- 解耦了数据和节点之间的关系,简化了节点的扩容和收缩的难度
- 节点自身来维护槽的映射关系,不需要客户端或者代理来维护槽分区的元数据
- 至此节点、槽、键之间的映射查询。
节点增加和删除
采用 Cluster 的集群方案,当节点增加和删除时,集群又是如何工作来保证服务的高可用?
下图展现一个 5 个节点构成的集群,每个节点平均大约负责 3276 个槽,以及通过计算公式映射到对应节点的对应槽的过程。
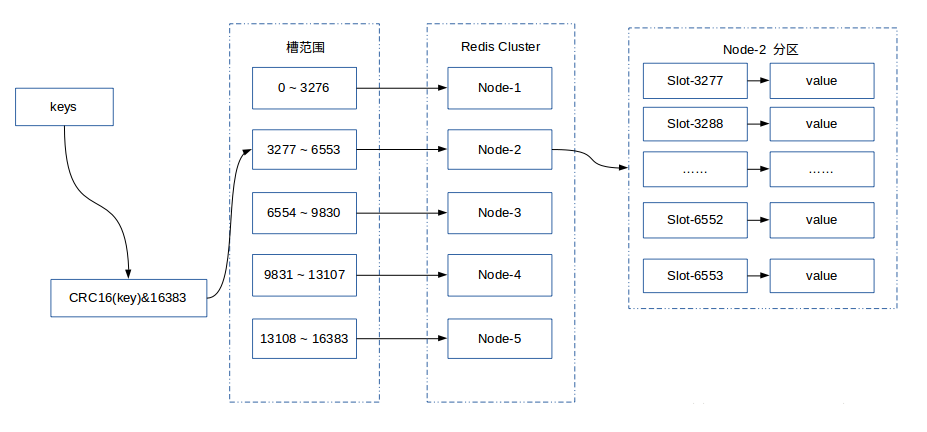
-
增加节点
当增加一个节点 Node-6 时,只需要把其他节点的某些哈希槽挪到新的节点就可以了。 -
移除节点
移除一个节点 Node-5 时,只需要把该节点上的哈希槽挪到其他的节点上就可以了。
在增加和删除节点,redis 的其他节点都不需要停机。
数据迁移
那么如何将槽的数据挪到其他的结点呢?
为了实现节点之间的数据迁移,节点之间必须相互连接。数据迁移分为两部分:
槽的迁移
现在要将 Master A 节点中的编号为 1,2,3 的槽迁移到 Master B 中
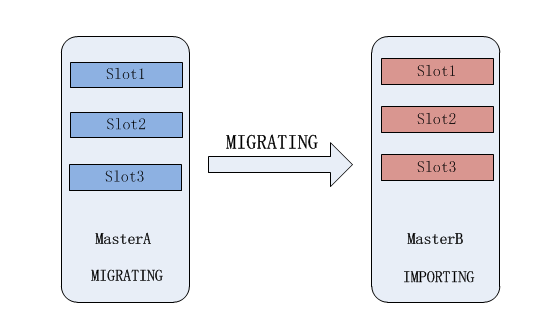
在迁移的中间状态下,槽 1,2,3 在 MasterA 节点的状态为
MIGRATING(迁移)
,在 MasterB 节点的状态为
IMPORTING(入口)
。
IMPORTING(入口)
状态是被迁移的槽在目标节点中出现的一种状态,准备迁移从A到B的时候,被迁移的槽的状态首先变为
IMPORTING(入口)
注意:
此时并不刷新 node 的映射关系
键空间的迁移
在满足了槽迁移的条件下,通过相关命令将 slot1, slot2, slot3 中的键空间从 A 迁移到B。迁移过程大概如下:
-
Master A 节点执行
DUMP命令,序列化要迁移的 key,并将数据发送给 Master B -
Master B 节点接受到要迁移的序列化的 key 之后执行
RESTORE命令反序列化为 key, 并保存 -
Master A 节点执行
DEL命令删除掉已迁移的 key
迁移完成之后,刷新 node 的映射关系
需要注意的是 : MIGRATE(迁移) 并不是原子的,如果在 MIGRATE 出现错误的情况可能会导致下面问题:
- 键空间在两个节点都存在;
- 键空间只存在第一个节点;
深挖细节
-
为什么不用一致性哈希,而用槽哈希分区,原因是什么?
Redis 使用的是 crc16 的简单算法,Redis 的作者认为crc16(key) mod 16384的效果已经不错了,虽然可能没有一致性哈希灵活,但实现比较简单,节点的增加和删除都比较方便 -
节点增加和删除的过程中,数据会不会丢失?
节点在数据迁移的时候数据会有备份,不会丢失
主从同步
我们已经了解了 Cluster 的集群的工作方式,那使用 Cluster 模式如何来实现主从同步?
其实主从同步还是使用的 Redis 本身的主从复制模式,将主从同步和 Cluster 模式结合起来的架构如下:
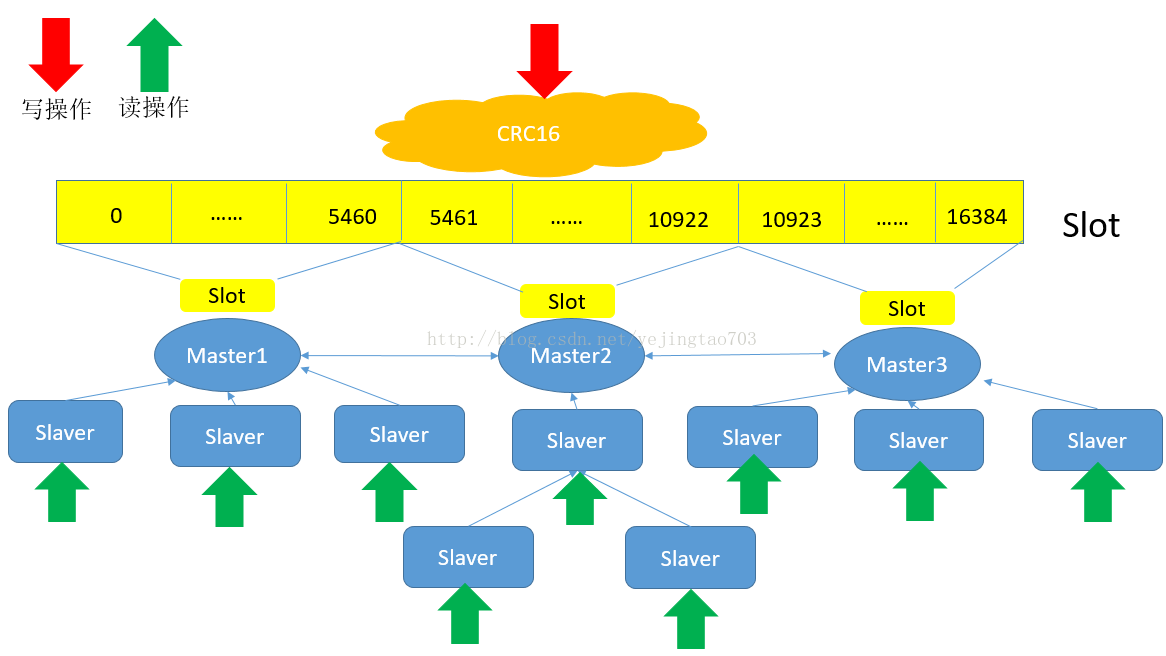
从图中可以看出,将多个 Master 节点作为 Cluster 的节点,每个 Master 的节点又增加多个 Slave 节点。并且数据读写分离。
如果想水平扩展读的并发能力,可以增加多个 Slave, 想水平扩展写的并发能力,可以增加多个 Master, 并且任何一个 Master 和 Slave 宕掉都不会影响服务稳定性。